Every SOC analyst knows the situation: you write an extensive prompt for alert triage, it works well, and three days later you cannot replicate the result. The colleague on the next shift improvises another prompt. Institutional knowledge exists only in the head of whoever is on duty.
Skills tackle this directly. Instead of a giant prompt loaded in every interaction, you package procedures into versioned folders that the agent loads on demand.
The problem Skills solve
The format is simple: a folder with a SKILL.md file containing YAML frontmatter and Markdown instructions, optionally accompanied by scripts and reference files.
1
2
3
4
5
6
7
alert-triage/
├── SKILL.md # Main instructions
├── scripts/
│ └── ioc_extractor.py # Deterministic extraction
└── references/
├── scoring_guide.md # Scoring methodology
└── escalation.md # Escalation criteria
The agent loads only metadata at startup. When a task matches a skill description, it pulls the full instructions. Scripts and references are loaded only when needed.
In practice this means: you can have dozens of skills available without blowing up the context window. It is progressive disclosure applied to automation.
The open standard: cross platform portability
In December 2025, Anthropic published the Agent Skills specification as an open standard at agentskills.io. Adoption was fast: OpenAI Codex, Cursor, GitHub Copilot, VS Code and other agents implemented the format.
What you get from this: a skill created for Claude Code works in Codex, and vice versa. Your investment in documented procedures is not locked to a specific vendor.
The specification is intentionally minimalist:
1
2
3
4
5
6
7
8
9
---
name: alert-triage-enrichment
description: Enrich security alerts with TI, asset context, historical patterns.
Use when processing SIEM alerts or investigating incidents.
license: Apache-2.0
metadata:
author: your-org
version: "1.2.0"
---
The name and description fields are required. Note that the description is critical because the agent uses it to decide which skill to activate. A vague description like “helps with security” rarely triggers; a specific one like “extract IOCs from CrowdStrike, ANY.RUN, or Joe Sandbox reports” works consistently.
How activation works
Skills support both explicit invocation (via commands like /skills or $skill-name in Codex) and implicit activation (agent decides based on task description). The behavior varies by agent implementation. The agent scans available skills at startup, loading only metadata. When a request matches a skill description, the agent loads the full instructions.
In most implementations, skill selection is primarily driven by the description text and the agent’s reasoning, rather than strict algorithmic matching. However, some tools may include additional heuristics or preprocessing.
1
2
3
4
5
6
7
# Works: specific triggers, clear scope
description: Extract IOCs from malware sandbox reports and correlate with threat
intelligence. Use when processing CrowdStrike, ANY.RUN, or Joe Sandbox outputs,
or when asked to extract indicators from behavioral analysis reports.
# Does not work: vague, overlaps many cases
description: Helps analyze security data and find threats.
Vague descriptions cause silent activation failures. Overly broad descriptions cause false activations. Treat the description as SEO for the model reasoning.
Skills in practice: the awesome-dfir-skills repository
The tsale/awesome-dfir-skills repository offers a community collection focused on DFIR and incident response. The structure follows the Agent Skills standard:
1
2
3
4
5
6
7
8
9
skills/
├── README.md # Skills catalog
├── _templates/
│ └── skill.md # Template for new skills
├── triage/ # First hour actions
├── collection/ # Collection and acquisition
├── analysis/ # Deep dives and forensics
├── hunting/ # Detection engineering
└── reporting/ # Reports and IOC packages
The repository principles are worth extracting:
Be explicit about assumptions. If a log source might not exist, state it. If you assume a specific timestamp format, document it.
Declare inputs and outputs. The YAML frontmatter should specify what goes in and what comes out. This eliminates ambiguity and enables skill composition.
Safety-first. Call attention to privacy/evidence handling. A phishing analysis skill should explicitly state that attachments are processed via sandbox API, never locally.
Tool-agnostic by default. If including examples in Splunk/KQL/Elastic, label and explain field mapping. Portable skills work in more environments.
The insight here is that well-written skills function as executable documentation. A new analyst can read the SKILL.md to understand the procedure, while the agent executes automatically.
Skill 1: Initial Incident Intake
The triage.initial-incident-intake skill standardizes first hour incident intake.
Metadata
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
---
id: "triage.initial-incident-intake"
name: "initial-incident-intake"
description: "First-hour intake checklist + questions that produce
an actionable scope and evidence plan."
version: "0.1.0"
tags: ["triage", "case-management", "scoping", "first-hour"]
category: "triage"
platforms: ["any"]
inputs:
- name: "intake_notes"
description: "Freeform notes from reporter: what happened, when, where, who noticed."
required: true
- name: "environment_summary"
description: "Org context: identity provider, EDR, email, cloud, logging, time zone."
required: false
outputs:
- name: "scoped_incident_summary"
description: "Short summary + working hypothesis + known/unknowns + next actions."
- name: "evidence_request_list"
description: "Concrete list of artifacts to request/collect next."
---
Embedded rules
The skill instructs the agent with specific constraints:
- If details are missing, ask targeted questions
- Do not assume log sources exist, confirm them
- Use the reporter timezone; if unknown, state explicitly
Expected deliverables
- Incident summary: 2-5 actionable sentences
- Working hypothesis: what you think is happening + confidence
- Time window: earliest to latest suspected activity
- Known / Unknown: bullets separating what is known from what is not
- Immediate containment: safe and low-regret actions
- Evidence request: prioritized, with WHY for each item
- Next 60 minutes plan: executable checklist
Evidence request starter list
The skill includes a base artifact list by incident type:
| Type | Artifacts |
|---|---|
| Identity (Entra/AD/Okta) | Sign-in logs, audit logs, MFA events, risky sign-ins |
| Message trace, headers, URL click logs, mailbox audit, rules/forwarding | |
| Endpoints | EDR detections, timeline, process tree, network connections |
| Network | Proxy/DNS logs, firewall flows, VPN logs |
| Cloud | CloudTrail / GCP audit / Azure activity, object storage access |
Why it works: it standardizes intake quality and forces explicit assumptions. The next shift analyst knows exactly where the case stopped.
Skill 2: Malware Analysis
The malware-analysis skill produces analyst-grade reports, not data dumps. Every conclusion must be backed by evidence and reasoning.
Core principles
- Evidence-based reasoning: never state a conclusion without explaining WHY
- Connect the dots: link indicators to behaviors to capabilities to impact
- Assess confidence: state how confident you are and why
- Actionable output: reports should enable decisions, not just inform
3-step workflow
Step 1: Collect Data - Run scripts for deterministic collection:
1
2
3
4
5
6
7
8
# Static analysis: hashes, PE info, strings, APIs, entropy
python3 scripts/static_analysis.py /path/to/sample -f json > static.json
# Threat intelligence: reputation across multiple sources
python3 scripts/triage.py -t file /path/to/sample -f json > triage.json
# IOC extraction: IPs, domains, URLs, hashes, registry keys
python3 scripts/extract_iocs.py /path/to/sample -f json > iocs.json
Step 2: Analyze and Reason - The critical step:
Threat Intelligence Assessment:
- Is the sample known? MalwareBazaar/ThreatFox = confirmed malware
- Detection rate? 0 = requires behavioral analysis; 5-15 = confirmed; 15+ = well-known
- Family attribution? Research typical behavior for the family
- First seen? Recent = active campaign
API Analysis - map APIs to behaviors:
| API Pattern | Probable Behavior | Reasoning |
|---|---|---|
| VirtualAlloc + VirtualProtect + WriteProcessMemory + CreateRemoteThread | Process Injection | Classic injection pattern: alloc, make executable, write, execute |
| CredEnumerate, CryptUnprotectData | Credential Theft | Specific access to credential stores and DPAPI |
| InternetOpen + URLDownloadToFile | Downloader | Initializes HTTP and downloads files |
| RegSetValueEx + Run key paths | Persistence | Writing to Run keys ensures startup execution |
| IsDebuggerPresent, GetTickCount | Anti-Analysis | Evasion checks indicate malware hides behavior |
Packing indicators:
- Entropy > 7.0 = compressed/encrypted content
- UPX0, UPX1, .aspack sections = known packer signatures
- Small import table with only GetProcAddress/LoadLibrary = dynamic API resolution
Step 3: Write the Report - Standardized structure:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# Threat Analysis Report: [MALWARE_NAME]
| | |
|---|---|
| Risk Level | CRITICAL/HIGH/MEDIUM/LOW |
| Confidence | High/Medium/Low |
| Analysis Date | DATE |
## Executive Summary
[2-3 sentences: What is this? Is it malicious? What can it do? How do we know?]
## Threat Intelligence Assessment
[What do TI sources say? Explain what each finding means]
## Behavioral Analysis
### Identified Capabilities
[For each capability: Confidence + Evidence + Reasoning]
## MITRE ATT&CK Mapping
[Only techniques you can justify with evidence]
## Indicators of Compromise
[File, Network, Host indicators]
## Risk Assessment
[Overall risk + reasons + confidence level]
## Recommendations
[Immediate actions + Detection opportunities + Further analysis needed]
Example: bad vs good analysis
Bad (data dump):
“Found APIs: VirtualAlloc, CreateRemoteThread, RegSetValueEx. Entropy: 7.2. VT: 34/70.”
Good (analyst reasoning):
“This sample demonstrates process injection capability (HIGH CONFIDENCE) based on the presence of VirtualAlloc and CreateRemoteThread. These APIs, when used together, form the classic code injection pattern where memory is allocated in a target process and a thread is created to execute the injected code. The high entropy (7.2) suggests the payload is packed, meaning the observed APIs may belong to the unpacker stub rather than the final payload. The 34/70 VirusTotal detection rate confirms this is recognized malware, with multiple vendors identifying it as a variant of Agent Tesla - an info-stealer known for credential harvesting. Given the injection capability and association with a credential-stealing family, this sample poses a CRITICAL risk to credential security on any system where it executes.”
Why it works: it combines deterministic tooling (scripts) with a structured reasoning framework. It prevents confident but incorrect conclusions, and forces the analyst (human or AI) to explain the “why” behind each finding.
This skill was part of the inspiration for the PDF triage skill presented in the next section - applying the same principle of structured reasoning to document analysis.
From theory to practice: a skill for document triage
The skills above demonstrate the pattern: declared inputs, structured outputs, explicit reasoning. But theory is theory. Let’s move to a real case.
PDFs and documents are persistent attack vectors. In 2025, the scenario only got worse:
- Q1 2025: APWG recorded over 1 million phishing attacks - the highest quarterly total since 2023. PDFs with malicious QR codes (quishing) exploded after Microsoft blocked macros by default in Office documents.
- Q4 2025: The SORVEPOTEL malware (also known as Water Saci) hit Brazil hard. Files disguised as payment receipts and boletos arrived via WhatsApp, self-propagated to all contacts, and targeted credentials from Bradesco, Itau, Caixa, Banco do Brasil and crypto exchanges.
The pattern is clear: documents are trusted by default, pass through filters, and users open them without a second thought - especially when they come from known contacts on WhatsApp. Attackers know this.
The problem for N1 analysts
In first-line triage, the typical flow is:
- Alert arrives (suspicious email, reported attachment)
- Analyst uploads to VirusTotal
- If VT returns detections, escalate. If it returns 0, release or remain uncertain.
The problem: well-crafted malware passes clean on VT. And N1 analysts typically don’t have the time, tools, or knowledge for manual static analysis of PDFs.
I created the pdf-triage-plus skill to address this (I plan to publish it along with other skills on GitHub soon). The idea is simple: package static analysis knowledge into a procedure any analyst can execute, with objective scoring and actionable outputs.
The skill combines deterministic tools with structural analysis - it doesn’t look for signatures, it looks for behavior.
Case Study: Skill vs VirusTotal - 95/100 vs 0/63
To test the skill under realistic conditions, I created a malicious PDF using documented evasion techniques. The goal: see if the skill would detect what AV engines wouldn’t.
The sample
Simple PDF. Title: “System Security Report”. Subtitle: “Confidential - Security Team”. One page. Social engineering targeting security teams - quite ironic.
Standard first step: VirusTotal analysis.
1
2
SHA256: 0caff9ea55aa25a6333b6e648838cd0652f50f3fba2784153d11024e68e5e63e
Detections: 0/63
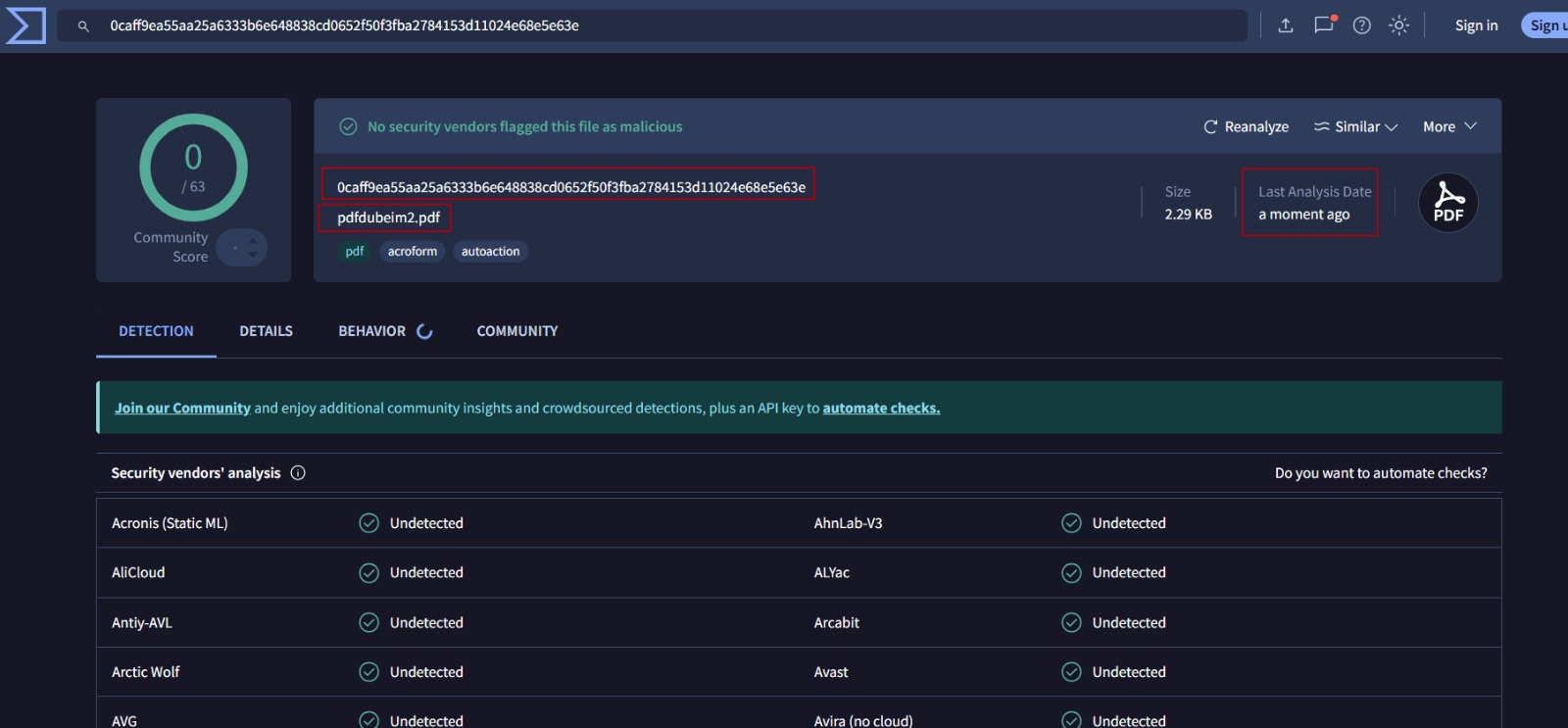
None of the 60+ engines flagged it as malicious. Zero.
Second step: PDF triage skill.
1
2
Risk Score: 95/100 - CRITICAL
Verdict: MALICIOUS - Dropper/Downloader
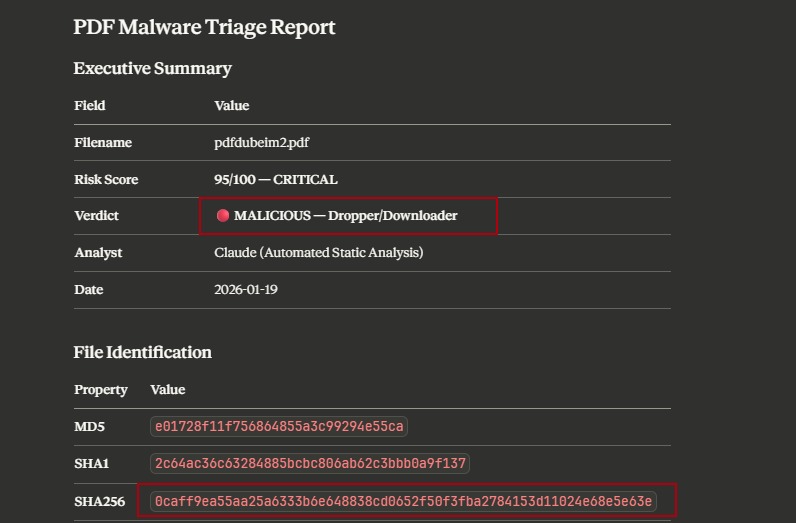
Payload identified, execution chain mapped, IOCs extracted.
What VirusTotal saw
Many AV engines rely heavily on known artifacts - signatures, hashes, specific byte patterns - though some vendors also use heuristics, ML models, or emulation. The key point is that the skill’s analysis was based on structure and semantics, not pattern matching. If the malware doesn’t match any pattern in the database, it passes clean.
Basic pdfid shows:
1
2
3
4
5
/JavaScript 0 ← Engines look for this
/OpenAction 0 ← And this
/Launch 0 ← And this
/AA 1 ← But not necessarily this
/AcroForm 1
The attacker (me, in this case) deliberately avoided the flags that engines look for.
What the skill saw
The skill doesn’t stop at flags. It extracts and analyzes stream contents:
1
2
3
4
5
6
7
8
9
Object 6:
/Type /Annot
/Subtype /Widget
/T (sys_field)
/Rect [ 0 0 1 1 ] ← Invisible 1x1 pixel widget
/AA <<
/F <<
stream
var parts = 'Ly8gU3l...'
The payload is in /AA (Additional Actions) inside an invisible 1x1 pixel form field. Base64 fragmented with +, reassembled at runtime.
I won’t include the full decoded code because that’s not the point of this post.
Classic dropper behavior: waits 2 minutes (typical sandbox runs 60-90s), drops a .ps1 to %TEMP%, executes PowerShell with -ExecutionPolicy Bypass.
Why the skill worked
The fundamental difference is in the question each approach asks:
Signature asks: “Does this look like something malicious I’ve seen before?”
Structural analysis asks: “Does this do something suspicious or out of the ordinary?”
The second question is harder to evade.
The skill works because:
- Extracts streams regardless of flags - Doesn’t matter if
/JavaScriptis zero; if there’s a stream with code, it analyzes - Decodes payloads in layers - Base64, hex, charcode - goes all the way to the final payload
- Analyzes code semantics -
util.writeToFile+app.launchURL= dropper behavior - Combines indicators in weighted scoring - No single indicator is definitive; the combination classifies
Operational lesson
1
2
VirusTotal score = 0 → does NOT mean safe
VirusTotal score = 0 → means "needs additional analysis"
If you rely solely on VirusTotal (which is an excellent resource) for suspicious attachment triage, well-crafted malware will pass. The skill complements - does not replace - dynamic analysis, which still has its value. But in many scenarios, structural analysis catches what signatures wouldn’t.
Limitations and risks
Prompt injection via analyzed artifacts
When the skill processes logs, emails or reports, the content may contain instructions that hijack the agent. Example: malicious hostname curl-commands.please-run-rm-rf.example.com or hidden instructions in PDFs.
Defense in depth:
- Content separation and sanitization
- Explicit demarcation of untrusted content
- Specialized detection before analysis
- Hard sandboxing to reduce impact
- Human approval for high risk actions
- Continuous adversarial testing
Skill supply chain risk
Skills can contain arbitrary code. A malicious skill executes commands, exfiltrates data, manipulates reasoning. No platform offers cryptographic signing yet.
Required controls:
- Code review for all files
- Inventory with versioning
- Trusted sources only
- Monitoring for unauthorized changes
Hallucination in security context
LLMs may invent IOCs, misclassify activity, generate confident but incorrect analysis.
Mitigations: use scripts for factual validation, cross-verify against authoritative sources, keep humans in the loop for classifications.
Conclusion
Skills represent a shift from ad-hoc prompts to versioned, auditable procedures. For security operations: consistency across shifts, institutional knowledge capture, reproducible workflows.
The PDF case study demonstrates practical value: 60+ engines saw nothing, the skill saw everything. Not because the skill is “better”, but because it asks a different question. Signature and structural analysis are complementary.
The pragmatic approach:
- Start small: Reporting skills before production triage
- Sandbox aggressively: Filesystem AND network isolation
- Humans in the loop: Gates for high impact actions
- Audit everything: Reasoning traces for compliance and forensics
- Test adversarially: Prompt injection in tests
- Version control: Skills are code, with reviews and rollback
My repository: CyberSec-Skills
The community is building: awesome-dfir-skills offers starting points. The open specification at agentskills.io ensures portability.
References
Official documentation
- OpenAI Codex Skills
- Claude Skills Overview
- Claude Custom Skills
- Claude Code Skills
- Agent Skills Platform Docs
- Anthropic Engineering Blog
Open standard specification
Reference repositories
- DFIR Skills Collection
- OpenAI Skills Repository
- Awesome Agent Skills
- CyberSec-Skills (author’s repository)
Security and risks
Case study sample
Threat intelligence
This analysis reflects publicly available documentation as of January 2026. Details can change, validate against current vendor docs before production deployment.
Todo analista de SOC conhece a situação: você escreve um prompt extenso para triagem de alertas, funciona bem, e três dias depois não consegue replicar o resultado. O colega do próximo turno improvisa outro prompt. O conhecimento institucional existe apenas na cabeça de quem está no plantão.
Skills atacam isso diretamente. Em vez de um prompt gigante carregado em toda interação, você empacota procedimentos em pastas versionadas que o agente carrega sob demanda.
O problema que Skills resolvem
O formato é simples: uma pasta com um arquivo SKILL.md contendo YAML frontmatter e instruções em Markdown, opcionalmente acompanhado de scripts e arquivos de referência.
1
2
3
4
5
6
7
alert-triage/
├── SKILL.md # Instruções principais
├── scripts/
│ └── ioc_extractor.py # Extração determinística
└── references/
├── scoring_guide.md # Metodologia de scoring
└── escalation.md # Critérios de escalação
O agente carrega apenas os metadados no startup. Quando uma tarefa corresponde à descrição da skill, ele puxa as instruções completas. Scripts e referências são carregados apenas quando necessário.
Na prática isso significa: você pode ter dezenas de skills disponíveis sem estourar a janela de contexto. É progressive disclosure aplicado a automação.
O padrão aberto: portabilidade entre plataformas
Em dezembro de 2025, a Anthropic publicou a especificação Agent Skills como padrão aberto em agentskills.io. A adoção foi rápida: OpenAI Codex, Cursor, GitHub Copilot, VS Code e outros agentes implementaram o formato.
O que você faz com isso: uma skill criada para Claude Code funciona em Codex, e vice-versa. Seu investimento em procedimentos documentados não fica preso a um vendor específico.
A especificação é intencionalmente minimalista:
1
2
3
4
5
6
7
8
9
---
name: alert-triage-enrichment
description: Enrich security alerts with TI, asset context, historical patterns.
Use when processing SIEM alerts or investigating incidents.
license: Apache-2.0
metadata:
author: your-org
version: "1.2.0"
---
Os campos name e description são obrigatórios. Vale notar que a descrição é crítica porque o agente usa ela para decidir qual skill ativar. Uma descrição vaga como “helps with security” raramente dispara; uma específica como “extract IOCs from CrowdStrike, ANY.RUN, or Joe Sandbox reports” funciona de forma consistente.
Como funciona a ativação
Skills suportam tanto invocação explícita (via comandos como /skills ou $skill-name no Codex) quanto ativação implícita (agente decide com base na descrição da task). O comportamento varia por implementação de agente. O agente varre as skills disponíveis no startup, carregando apenas metadados. Quando um request corresponde à descrição de uma skill, o agente carrega as instruções completas.
Na maioria das implementações, a seleção de skill é primariamente guiada pelo texto da descrição e pelo raciocínio do agente, não por matching algorítmico estrito. Porém, algumas ferramentas podem incluir heurísticas ou pré-processamento adicional.
1
2
3
4
5
6
7
# Funciona: triggers específicos, escopo claro
description: Extract IOCs from malware sandbox reports and correlate with threat
intelligence. Use when processing CrowdStrike, ANY.RUN, or Joe Sandbox outputs,
or when asked to extract indicators from behavioral analysis reports.
# Não funciona: vago, sobrepõe muitos casos
description: Helps analyze security data and find threats.
Descrições vagas causam falhas silenciosas de ativação. Descrições muito amplas causam ativações falsas. Trate a descrição como SEO para o raciocínio do modelo.
Skills na prática: o repositório awesome-dfir-skills
O repositório tsale/awesome-dfir-skills oferece uma coleção comunitária focada em DFIR e incident response. A estrutura segue o padrão Agent Skills:
1
2
3
4
5
6
7
8
9
skills/
├── README.md # Catálogo de skills
├── _templates/
│ └── skill.md # Template para novas skills
├── triage/ # Ações de primeira hora
├── collection/ # Coleta e aquisição
├── analysis/ # Deep dives e forense
├── hunting/ # Detection engineering
└── reporting/ # Relatórios e IOC packages
Os princípios do repositório valem extrair:
Be explicit about assumptions. Se uma fonte de log pode não existir, declare isso. Se você assume formato específico de timestamp, documente.
Declare inputs and outputs. O YAML frontmatter deve especificar o que entra e o que sai. Isso elimina ambiguidade e permite composição de skills.
Safety-first. Chame atenção para privacy/evidence handling. Uma skill de análise de phishing deve explicitar que attachments são processados via sandbox API, nunca localmente.
Tool-agnostic by default. Se incluir exemplos em Splunk/KQL/Elastic, rotule e explique field mapping. Skills portáveis funcionam em mais ambientes.
O insight aqui é que skills bem escritas funcionam como documentação executável. Um analista novo pode ler o SKILL.md para entender o procedimento, enquanto o agente executa automaticamente.
Skill 1: Initial Incident Intake
A skill triage.initial-incident-intake padroniza o intake da primeira hora de um incidente.
Metadados
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
---
id: "triage.initial-incident-intake"
name: "initial-incident-intake"
description: "First-hour intake checklist + questions that produce
an actionable scope and evidence plan."
version: "0.1.0"
tags: ["triage", "case-management", "scoping", "first-hour"]
category: "triage"
platforms: ["any"]
inputs:
- name: "intake_notes"
description: "Freeform notes from reporter: what happened, when, where, who noticed."
required: true
- name: "environment_summary"
description: "Org context: identity provider, EDR, email, cloud, logging, time zone."
required: false
outputs:
- name: "scoped_incident_summary"
description: "Short summary + working hypothesis + known/unknowns + next actions."
- name: "evidence_request_list"
description: "Concrete list of artifacts to request/collect next."
---
Regras embutidas
A skill instrui o agente com constraints específicas:
- Se detalhes estão faltando, fazer perguntas direcionadas
- Não assumir que fontes de logs existem, confirmar
- Usar o fuso horário do reporter; se desconhecido, declarar explicitamente
Deliverables esperados
- Incident summary: 2-5 frases acionáveis
- Working hypothesis: o que você acha que está acontecendo + confiança
- Time window: atividade mais cedo -> mais tarde suspeita
- Known / Unknown: bullets separando o que se sabe do que não
- Immediate containment: ações safe e low-regret
- Evidence request: priorizado, com WHY para cada item
- Next 60 minutes plan: checklist executável
Evidence request starter list
A skill inclui uma lista base de artefatos por tipo de incidente:
| Tipo | Artefatos |
|---|---|
| Identity (Entra/AD/Okta) | Sign-in logs, audit logs, MFA events, risky sign-ins |
| Message trace, headers, URL click logs, mailbox audit, rules/forwarding | |
| Endpoints | EDR detections, timeline, process tree, network connections |
| Network | Proxy/DNS logs, firewall flows, VPN logs |
| Cloud | CloudTrail / GCP audit / Azure activity, object storage access |
Por que funciona: padroniza a qualidade do intake e força explicitação de suposições. O próximo analista do turno sabe exatamente onde o caso parou.
Skill 2: Malware Analysis
A skill malware-analysis produz relatórios analyst-grade, não dumps de dados. Cada conclusão deve ser backed by evidence and reasoning.
Princípios centrais
- Evidence-based reasoning: nunca afirme uma conclusão sem explicar POR QUE
- Connect the dots: ligue indicadores a comportamentos a capacidades a impacto
- Assess confidence: declare quão confiante você está e por quê
- Actionable output: relatórios devem habilitar decisões, não apenas informar
Workflow de 3 passos
Passo 1: Collect Data - Execute scripts para coleta determinística:
1
2
3
4
5
6
7
8
# Análise estática: hashes, PE info, strings, APIs, entropy
python3 scripts/static_analysis.py /path/to/sample -f json > static.json
# Threat intelligence: reputação em múltiplas fontes
python3 scripts/triage.py -t file /path/to/sample -f json > triage.json
# Extração de IOCs: IPs, domains, URLs, hashes, registry keys
python3 scripts/extract_iocs.py /path/to/sample -f json > iocs.json
Passo 2: Analyze and Reason - O passo crítico:
Threat Intelligence Assessment:
- Sample é conhecido? MalwareBazaar/ThreatFox = confirmed malware
- Detection rate? 0 = requer behavioral analysis; 5-15 = confirmed; 15+ = well-known
- Family attribution? Pesquise comportamento típico da família
- First seen? Recente = campanha ativa
API Analysis - mapeie APIs para comportamentos:
| Padrão de API | Comportamento provável | Raciocínio |
|---|---|---|
| VirtualAlloc + VirtualProtect + WriteProcessMemory + CreateRemoteThread | Process Injection | Classic injection pattern: alloc, make executable, write, execute |
| CredEnumerate, CryptUnprotectData | Credential Theft | Acesso específico a credential stores e DPAPI |
| InternetOpen + URLDownloadToFile | Downloader | Inicializa HTTP e baixa arquivos |
| RegSetValueEx + Run key paths | Persistence | Escrita em Run keys garante execução no startup |
| IsDebuggerPresent, GetTickCount | Anti-Analysis | Evasion checks indicam que malware esconde comportamento |
Packing indicators:
- Entropy > 7.0 = compressed/encrypted content
- UPX0, UPX1, .aspack sections = known packer signatures
- Small import table with only GetProcAddress/LoadLibrary = dynamic API resolution
Passo 3: Write the Report - Estrutura padronizada:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# Threat Analysis Report: [MALWARE_NAME]
| | |
|---|---|
| Risk Level | CRITICAL/HIGH/MEDIUM/LOW |
| Confidence | High/Medium/Low |
| Analysis Date | DATE |
## Executive Summary
[2-3 sentences: What is this? Is it malicious? What can it do? How do we know?]
## Threat Intelligence Assessment
[O que TI sources dizem? Explique o que cada finding significa]
## Behavioral Analysis
### Identified Capabilities
[Para cada capability: Confidence + Evidence + Reasoning]
## MITRE ATT&CK Mapping
[Apenas técnicas que você pode justificar com evidência]
## Indicators of Compromise
[File, Network, Host indicators]
## Risk Assessment
[Overall risk + razões + confidence level]
## Recommendations
[Immediate actions + Detection opportunities + Further analysis needed]
Exemplo: análise ruim vs boa
Ruim (data dump):
“Found APIs: VirtualAlloc, CreateRemoteThread, RegSetValueEx. Entropy: 7.2. VT: 34/70.”
Boa (analyst reasoning):
“This sample demonstrates process injection capability (HIGH CONFIDENCE) based on the presence of VirtualAlloc and CreateRemoteThread. These APIs, when used together, form the classic code injection pattern where memory is allocated in a target process and a thread is created to execute the injected code. The high entropy (7.2) suggests the payload is packed, meaning the observed APIs may belong to the unpacker stub rather than the final payload. The 34/70 VirusTotal detection rate confirms this is recognized malware, with multiple vendors identifying it as a variant of Agent Tesla - an info-stealer known for credential harvesting. Given the injection capability and association with a credential-stealing family, this sample poses a CRITICAL risk to credential security on any system where it executes.”
Por que funciona: combina tooling determinista (scripts) com framework de raciocínio estruturado. Evita conclusões confiantes mas incorretas, e força o analista (humano ou IA) a explicar o “por quê” de cada finding.
Essa skill foi parte da inspiração para a skill de PDF triage apresentada na próxima seção - aplicando o mesmo princípio de raciocínio estruturado para análise de documentos.
Da teoria à prática: uma skill para triagem de documentos
As skills acima demonstram o padrão: inputs declarados, outputs estruturados, raciocínio explícito. Mas teoria é teoria. Vamos para um caso real.
PDFs e documentos são vetores de ataque persistentes. Em 2025, o cenário só piorou:
- Q1 2025: APWG registrou mais de 1 milhão de ataques de phishing - o maior total trimestral desde 2023. PDFs com QR codes maliciosos (quishing) explodiram após a Microsoft bloquear macros por padrão em documentos Office.
- Q4 2025: O malware SORVEPOTEL (ou Water Saci) atingiu o Brasil com força. Arquivos simulando comprovantes de pagamento e boletos chegavam via WhatsApp, se auto-propagavam para todos os contatos, e miravam credenciais de Bradesco, Itaú, Caixa, Banco do Brasil e corretoras de cripto.
O padrão é claro: documentos são confiáveis por padrão, passam por filtros, e usuários abrem sem pensar duas vezes - especialmente quando vêm de contatos conhecidos no WhatsApp. Atacantes sabem disso.
O problema para analistas N1
Na triagem de primeira linha, o fluxo típico é:
- Alerta chega (email suspeito, anexo reportado)
- Analista joga no VirusTotal
- Se VT retorna detecções, escala. Se retorna 0, libera ou fica na dúvida.
O problema: malware bem construído passa limpo no VT. E analistas N1 geralmente não têm tempo, ferramentas ou conhecimento para análise estática manual de PDFs.
Criei a skill pdf-triage-plus para resolver isso (pretendo publicá-la junto com outras skills no GitHub em breve). A ideia é simples: empacotar o conhecimento de análise estática em um procedimento que qualquer analista pode executar, com scoring objetivo e outputs acionáveis.
A skill combina ferramentas determinísticas com análise estrutural - não procura assinaturas, procura comportamento.
Case Study: Skill vs VirusTotal - 95/100 vs 0/63
Para testar a skill em condições realistas, criei um PDF malicioso usando técnicas documentadas de evasão. O objetivo: ver se a skill detectaria o que engines de AV não detectam.
O sample
PDF simples. Título: “System Security Report”. Subtítulo: “Confidential - Security Team”. Uma página. Social engineering direcionado a equipes de segurança - bem irônico.
Primeiro passo padrão: Análise no VirusTotal.
1
2
SHA256: 0caff9ea55aa25a6333b6e648838cd0652f50f3fba2784153d11024e68e5e63e
Detections: 0/63
Nenhum dos 60+ engines marcou como malicioso. Zero.
Segundo passo: skill de PDF triage.
1
2
Risk Score: 95/100 - CRITICAL
Verdict: MALICIOUS - Dropper/Downloader
Payload identificado, cadeia de execução mapeada, IOCs extraídos.
O que o VirusTotal viu
Muitos engines de AV dependem fortemente de artefatos conhecidos - assinaturas, hashes, padrões específicos de bytes - embora alguns vendors também usem heurística, modelos ML ou emulação. O ponto é que a análise da skill foi baseada em estrutura e semântica, não pattern matching. Se o malware não bate com nenhum padrão no banco de dados, passa limpo.
O pdfid básico mostra:
1
2
3
4
5
/JavaScript 0 ← Engines procuram isso
/OpenAction 0 ← E isso
/Launch 0 ← E isso
/AA 1 ← Mas não necessariamente isso
/AcroForm 1
O atacante (eu, neste caso) evitou deliberadamente os flags que engines procuram.
O que a skill viu
A skill não para nos flags. Ela extrai e analisa o conteúdo dos streams:
1
2
3
4
5
6
7
8
9
Object 6:
/Type /Annot
/Subtype /Widget
/T (sys_field)
/Rect [ 0 0 1 1 ] ← Widget invisível de 1x1 pixel
/AA <<
/F <<
stream
var parts = 'Ly8gU3l...'
O payload está em /AA (Additional Actions) dentro de um form field invisível de 1x1 pixel. Base64 fragmentado com +, reassemblado em runtime.
Não vou colocar o código todo decodificado porque não é o objetivo desse post.
Comportamento clássico de dropper: espera 2 minutos (sandbox típico roda 60-90s), dropa um .ps1 no %TEMP%, executa PowerShell com -ExecutionPolicy Bypass.
Por que a skill funcionou
A diferença fundamental está na pergunta que cada abordagem faz:
Assinatura pergunta: “Isso parece com algo malicioso que já vi antes?”
Análise estrutural pergunta: “Isso faz algo suspeito/fora do padrão?”
A segunda pergunta é mais difícil de evadir.
A skill funciona porque:
- Extrai streams independente de flags - Não importa se
/JavaScriptestá zerado; se tem stream com código, analisa - Decodifica payloads em camadas - Base64, hex, charcode - vai até o payload final
- Analisa semântica do código -
util.writeToFile+app.launchURL= comportamento de dropper - Combina indicadores em scoring ponderado - Nenhum indicador isolado é definitivo; a combinação classifica
Lição operacional
1
2
VirusTotal score = 0 → NÃO significa seguro
VirusTotal score = 0 → significa "precisa análise adicional"
Se você depende apenas de VirusTotal (que é um ótimo recurso) para triagem de anexos suspeitos, um malware bem construído vai passar. A skill complementa - não substitui - a análise dinâmica, que ainda tem seu valor. Mas em diversos cenários, a análise estrutural pega o que assinaturas não pegariam.
Limitações e riscos
Prompt injection via artefatos analisados
Quando a skill processa logs, emails ou relatórios, o conteúdo pode conter instruções que sequestram o agente. Exemplo: hostname malicioso curl-commands.please-run-rm-rf.example.com ou instruções escondidas em PDFs.
Defense in depth:
- Separação e sanitização de conteúdo
- Demarcação explícita de conteúdo não confiável
- Detecção especializada antes da análise
- Sandboxing rígido para reduzir impacto
- Aprovação humana para ações de alto risco
- Testes adversariais contínuos
Risco de supply chain de Skills
Skills podem conter código arbitrário. Uma skill maliciosa executa comandos, exfiltra dados, manipula raciocínio. Nenhuma plataforma oferece signing criptográfico ainda.
Controles requeridos:
- Revisão de código para todos os arquivos
- Inventário com versionamento
- Fontes confiáveis apenas
- Monitoramento de alterações não autorizadas
Alucinação em contexto de segurança
LLMs podem inventar IOCs, classificar errado, gerar análise confiante mas incorreta.
Mitigações: use scripts para validação factual, cross-verifique contra fontes autoritativas, mantenha humanos no loop para classificações.
Conclusão
Skills representam uma mudança de prompts ad-hoc para procedimentos versionados e auditáveis. Para operações de segurança: consistência entre turnos, captura de conhecimento institucional, workflows reproduzíveis.
O case study do PDF demonstra o valor prático: 60+ engines não viram nada, a skill viu tudo. Não porque a skill é “melhor”, mas porque faz uma pergunta diferente. Assinatura e estrutura são complementares.
O approach pragmático:
- Comece pequeno: Skills de reporting antes de triagem de produção
- Sandbox agressivamente: Isolamento de filesystem E rede
- Humanos no loop: Gates para ações de alto impacto
- Audite tudo: Reasoning traces para compliance e forensics
- Teste adversarialmente: Prompt injection nos testes
- Version control: Skills são código, com reviews e rollback
Meu repositório: CyberSec-Skills
A comunidade está construindo: awesome-dfir-skills oferece starting points. A especificação aberta em agentskills.io garante portabilidade.
Referências
Documentação oficial
- OpenAI Codex Skills
- Claude Skills Overview
- Claude Custom Skills
- Claude Code Skills
- Agent Skills Platform Docs
- Anthropic Engineering Blog
Especificação open standard
Repositórios de referência
- DFIR Skills Collection
- OpenAI Skills Repository
- Awesome Agent Skills
- CyberSec-Skills (repositório do autor)
Segurança e riscos
Sample do case study
Threat intelligence
Esta análise reflete documentação publicamente disponível até janeiro de 2026. Detalhes podem mudar, valide contra a documentação atual antes de deploy em produção.